PySpark Là Gì ? Bắt Đầu Với PySpark

Khám phá PySpark là gì và cách sử dụng nó qua các ví dụ cụ thể. Nếu bạn là một người đam mê khoa học dữ liệu, có lẽ bạn đã quen với việc lưu trữ các tệp trên thiết bị cục bộ và xử lý chúng bằng các ngôn ngữ như R và Python. Tuy nhiên, các máy trạm cục bộ có những giới hạn và không thể xử lý các tập dữ liệu cực lớn.
Đây là lúc một hệ thống xử lý phân tán như Apache Spark trở nên hữu ích. Hệ thống xử lý phân tán là một cấu hình trong đó nhiều bộ xử lý được sử dụng để chạy một ứng dụng. Thay vì cố gắng xử lý các tập dữ liệu lớn trên một máy tính đơn lẻ, nhiệm vụ có thể được chia nhỏ giữa nhiều thiết bị và các thiết bị này giao tiếp với nhau.
Tất cả điều này mang lại một sự đổi mới đầy thú vị. Để tiếp tục với bài viết này, bạn có thể thực hành các bài tập thực hành với khóa học “Giới Thiệu Về PySpark”, điều này sẽ mở ra cánh cửa cho bạn trong lĩnh vực tính toán song song. Khả năng phân tích dữ liệu và huấn luyện các mô hình học máy trên các tập dữ liệu lớn là một kỹ năng quý giá và có khả năng làm việc với các khung dữ liệu lớn như Apache Spark sẽ giúp bạn nổi bật trong ngành.
PySpark Là Gì?
PySpark là một giao diện lập trình ứng dụng (API) mở rộng của Apache Spark dành cho Python. PySpark cho phép bạn viết các lệnh bằng Python và SQL để thao tác và phân tích dữ liệu trong môi trường xử lý phân tán. Với PySpark, các nhà khoa học dữ liệu có thể thao tác dữ liệu, xây dựng các pipeline học máy và tối ưu hóa các mô hình.
Nhiều nhà khoa học dữ liệu đã quen với Python và sử dụng nó để triển khai các quy trình học máy. PySpark cho phép họ làm việc với một ngôn ngữ quen thuộc trên các tập dữ liệu lớn phân tán. Apache Spark cũng có thể được sử dụng với các ngôn ngữ lập trình khoa học dữ liệu khác như R.
Tại Sao Sử Dụng PySpark?
Lý do mà các công ty chọn sử dụng PySpark là bởi tốc độ xử lý dữ liệu lớn của nó. PySpark nhanh hơn các thư viện như Pandas và Dask, và có thể xử lý lượng dữ liệu lớn hơn nhiều so với các khung này. Ví dụ, nếu bạn có lượng dữ liệu lớn hơn petabyte, Pandas và Dask sẽ không thể xử lý được, nhưng PySpark có thể dễ dàng làm được.
Hơn nữa, PySpark cung cấp tính năng khôi phục sau lỗi (fault tolerance), nghĩa là nó có khả năng phục hồi sau khi xảy ra lỗi. Khung dữ liệu này cũng có tính toán trong bộ nhớ (in-memory computation) và được lưu trữ trong bộ nhớ truy cập ngẫu nhiên (RAM).
Cài Đặt PySpark
Để cài đặt Apache Spark và PySpark, bạn cần có các phần mềm sau trên thiết bị của mình:
- Python: Nếu chưa có Python, bạn có thể cài đặt theo hướng dẫn dành cho nhà phát triển Python.
- Java: Bạn cũng cần cài đặt Java. Hãy làm theo hướng dẫn cài đặt cho hệ điều hành bạn đang sử dụng.
- Jupyter Notebook: Đây là ứng dụng web để viết mã, hiển thị phương trình, trực quan hóa và văn bản.
Sau khi đã có đầy đủ yêu cầu, bạn có thể cài đặt Apache Spark và PySpark bằng lệnh sau trong Jupyter Notebook:
!pip install pyspark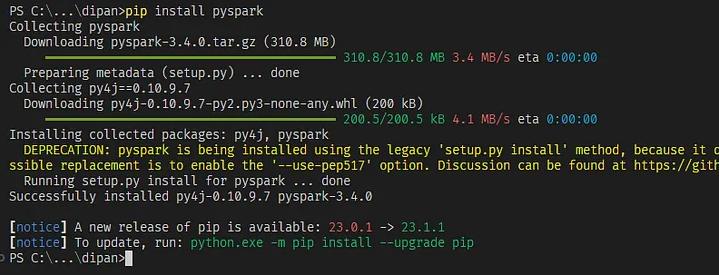
Ví Dụ Sử Dụng PySpark
Sau khi cài đặt PySpark, chúng ta sẽ thực hiện một dự án phân đoạn khách hàng sử dụng thư viện này. Phân đoạn khách hàng là một kỹ thuật tiếp thị để xác định và nhóm các người dùng có đặc điểm tương tự.
Bước 1: Tạo SparkSession
SparkSession là điểm khởi đầu cho tất cả các chức năng trong Spark và cần thiết nếu bạn muốn xây dựng một DataFrame trong PySpark:
spark = SparkSession.builder.appName("Pyspark Tutorial").getOrCreate()Bước 2: Tạo DataFrame
Chúng ta có thể đọc tập dữ liệu đã tải về:
df = spark.read.csv('data.csv', header=True)Bước 3: Phân Tích Dữ Liệu Khám Phá (Exploratory Data Analysis)
Chúng ta có thể sử dụng các chức năng như groupBy() và orderBy() để hiểu rõ hơn về dữ liệu.
Bước 4: Tiền Xử Lý Dữ Liệu
Chúng ta cần chuẩn bị dữ liệu để đưa vào mô hình học máy. Các bước tiền xử lý bao gồm chuyển đổi kiểu dữ liệu và chuẩn hóa dữ liệu.
Bước 5: Xây Dựng Mô Hình Học Máy
Chúng ta sẽ sử dụng thuật toán K-Means để phân đoạn khách hàng:
from pyspark.ml.clustering import KMeans
kmeans = KMeans().setK(4).setSeed(1)
model = kmeans.fit(data)Bước 6: Phân Tích Cụm
Sau khi đã xây dựng mô hình, chúng ta sẽ phân tích các cụm khách hàng để hiểu rõ hơn về đặc điểm của từng nhóm.
Lợi Ích và Hạn Chế Của PySpark
Lợi ích của PySpark bao gồm tốc độ xử lý nhanh, khả năng làm việc với dữ liệu lớn, và tính năng khôi phục sau lỗi. Hạn chế của nó bao gồm việc gỡ lỗi phức tạp và khó khăn trong việc xử lý các vấn đề chất lượng dữ liệu.
Cách Bắt Đầu Với PySpark
Trước khi sử dụng PySpark, bạn cần cài đặt và làm quen với Python, Jupyter Notebook, Java và Apache Spark. Bạn có thể tham gia các khóa học trực tuyến để học cách đọc tệp, phân tích dữ liệu và sử dụng PySpark cho học máy.
Kết Luận
PySpark là một công cụ mạnh mẽ để thực hiện phân tích dữ liệu lớn và xây dựng các mô hình học máy. Việc thành thạo PySpark và xử lý dữ liệu phân tán là rất quan trọng để xử lý các tập dữ liệu lớn đang ngày càng phổ biến trong thế giới hiện đại.
Hãy tiếp tục xem thêm các bài viết khác của chúng tôi tại ThueGPU.vn hoặc Fanpage. Nếu có nhu cầu Thuê máy chủ GPU, CLOUD GPU hãy liên hệ với chúng tôi.
CÔNG TY TNHH CÔNG NGHỆ EZ
- VP HCM: 211 Đường số 5, Lake View City, An Phú, Thủ Đức.
- Tel: 0877223579
- Email: [email protected]